
How It Works#
This part of the documentation includes a high-level explanation of how Camelot extracts tables from PDF files.
You can choose between the following table parsing methods, Stream, Lattice, Network and Hybrid. Where Hybrid is a combination of the Network and Lattice parser.
Tip
For a side-by-side visual comparison of the parsers use our comparison notebook. ![]()
Stream#
Stream can be used to parse tables that have whitespaces between cells to simulate a table structure. It is built on top of playa’s PDFMiner-compatible functionality for grouping characters on a page into words and sentences, using margins.
Words on the PDF page are grouped into text rows based on their y axis overlaps.
Textedges are calculated and then used to guess interesting table areas on the PDF page. You can read Anssi Nurminen’s master’s thesis to know more about this table detection technique. [See pages 20, 35 and 40]
The number of columns inside each table area are then guessed. This is done by calculating the mode of number of words in each text row. Based on this mode, words in each text row are chosen to calculate a list of column x ranges.
Words that lie inside/outside the current column x ranges are then used to extend the current list of columns.
Finally, a table is formed using the text rows’ y ranges and column x ranges and words found on the page are assigned to the table’s cells based on their x and y coordinates.
Lattice#
Lattice is more deterministic in nature, and it does not rely on guesses. It can be used to parse tables that have demarcated lines between cells, and it can automatically parse multiple tables present on a page.
It starts by converting the PDF page to an image using an image conversion backend (default pdfium), and then processes it to get horizontal and vertical line segments by applying a set of morphological transformations (erosion and dilation) using OpenCV.
Note
That image-based (raster) line detection is the default. When a PDF
draws its rules as native vector graphics, those exact line
coordinates are already in the document — and they sometimes render
too faintly for the rasteriser to pick up. The engine='combined'
option (see Line-detection engine: raster, combined, auto) reads those vector lines
directly and unions them into the rasterised line masks before the
grid below is reconstructed, so faintly-ruled vector tables are still
found. Because raster detection always runs first, the vector lines
can only add to the result — 'combined' is never worse than the
default 'raster'.
Let’s see how Lattice processes the second page of this PDF, step-by-step.
Line segments are detected.
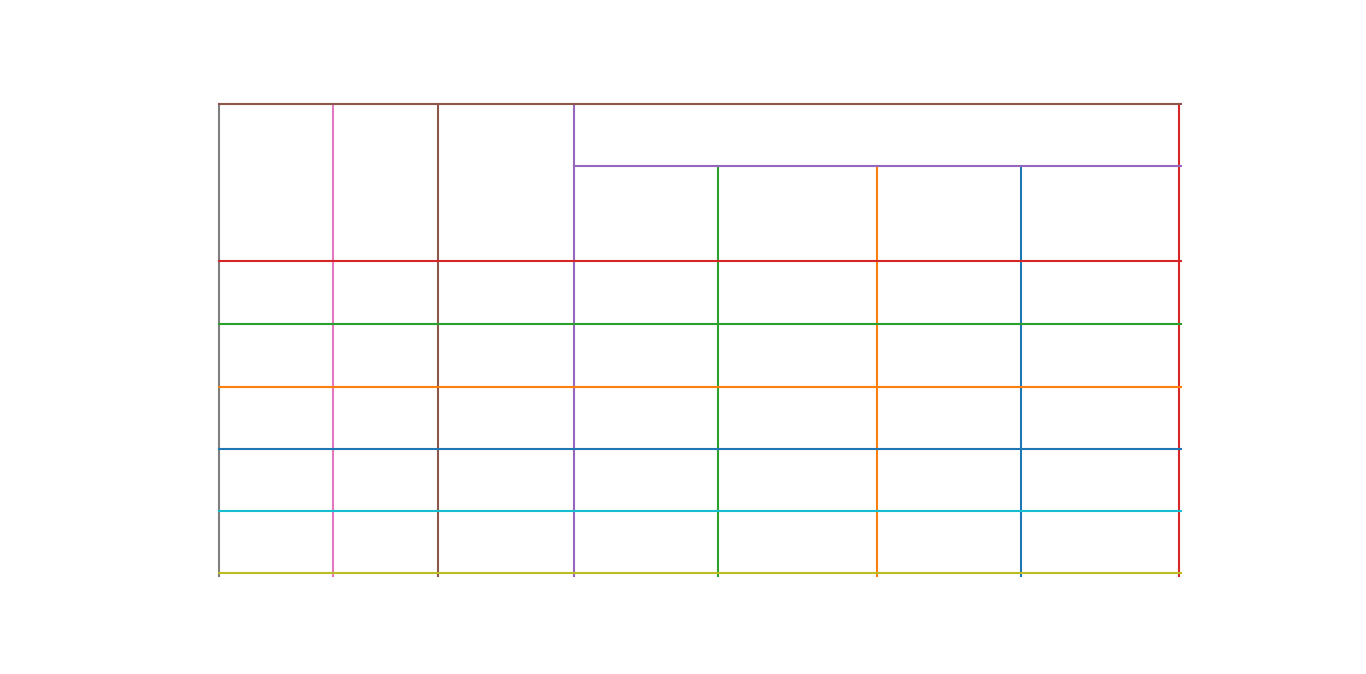
Line intersections are detected, by overlapping the detected line segments and “and”ing their pixel intensities.
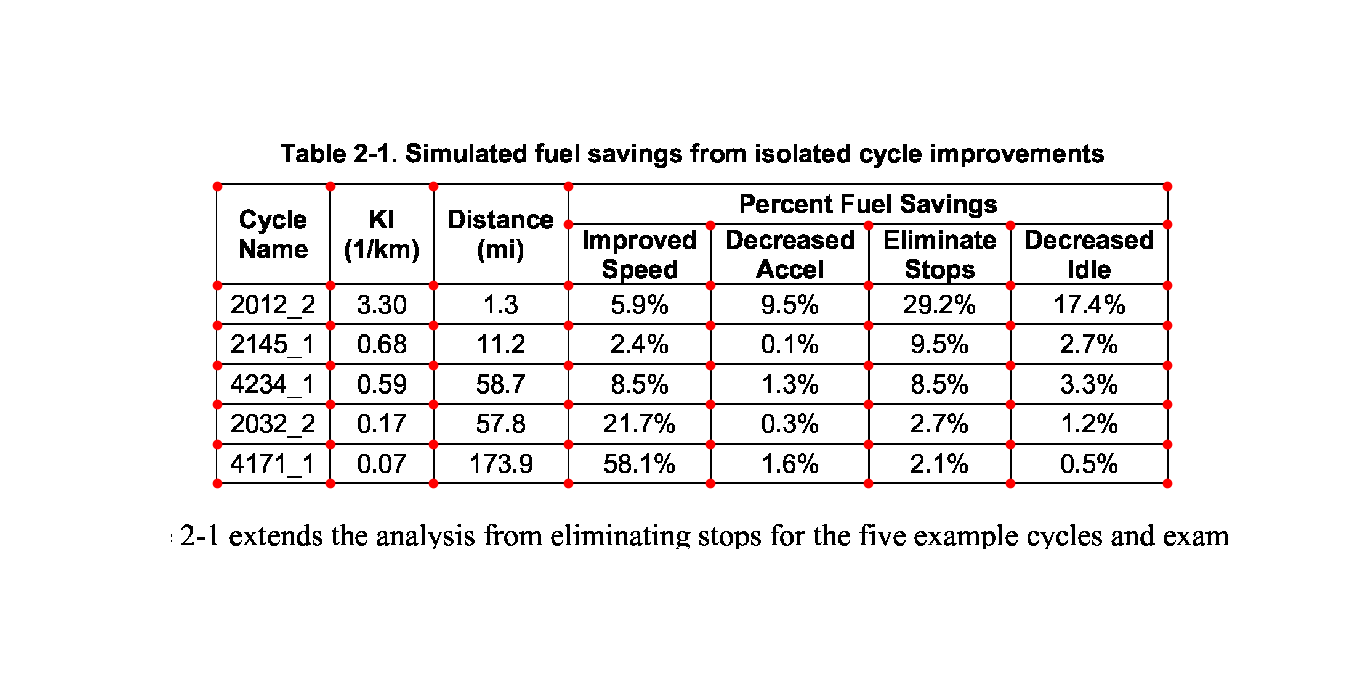
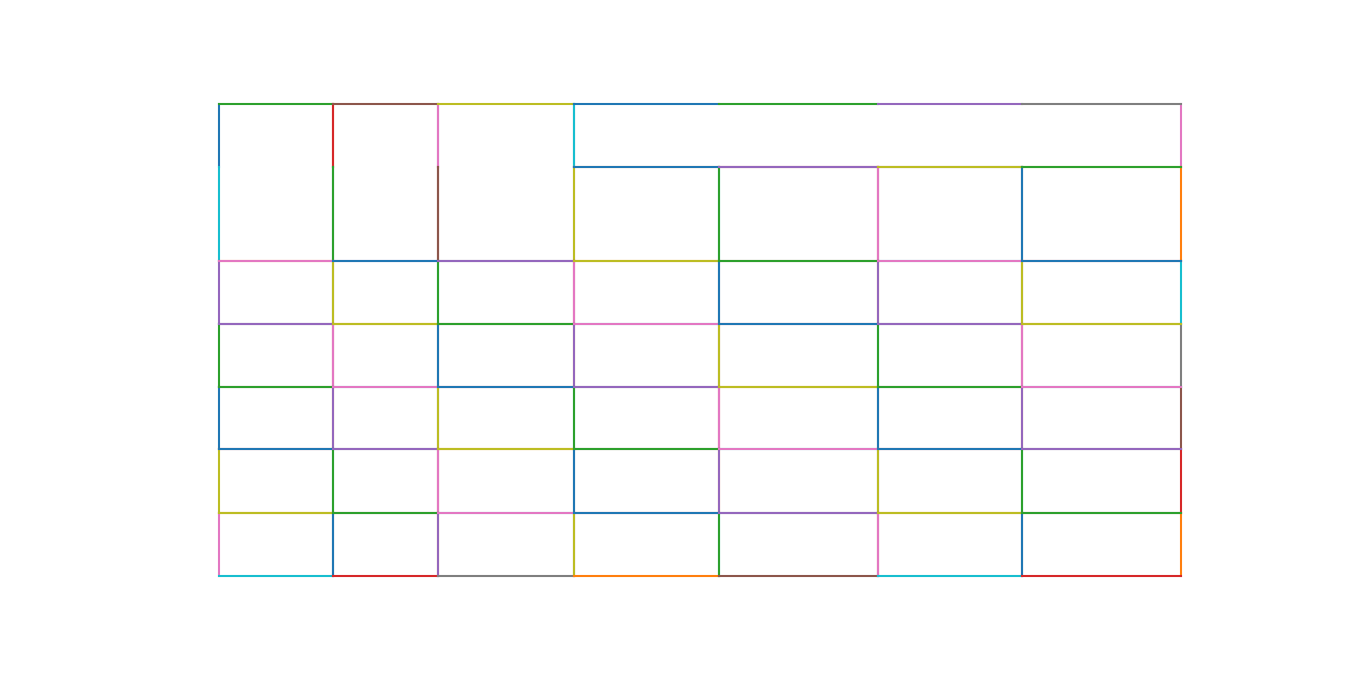
Table boundaries are computed by overlapping the detected line segments again, this time by “or”ing their pixel intensities.
Since dimensions of the PDF page and its image vary, the detected table boundaries, line intersections, and line segments are scaled and translated to the PDF page’s coordinate space, and a representation of the table is created.

Spanning cells are detected using the line segments and line intersections.
Finally, the words found on the page are assigned to the table’s cells based on their x and y coordinates.
Network#
Tip
The mechanism of the Network and Hybrid parser can best be understood by using the following notebook:
The network parser is text-based: it relies on the bounding boxes of the text elements encoded in the .pdf document to identify patterns indicative of a table.
The parser starts by enumerating the bounding boxes of every text element on the page — typically horizontal-running boxes (the bulk of the text) and occasional vertical-running boxes (rare in most documents).
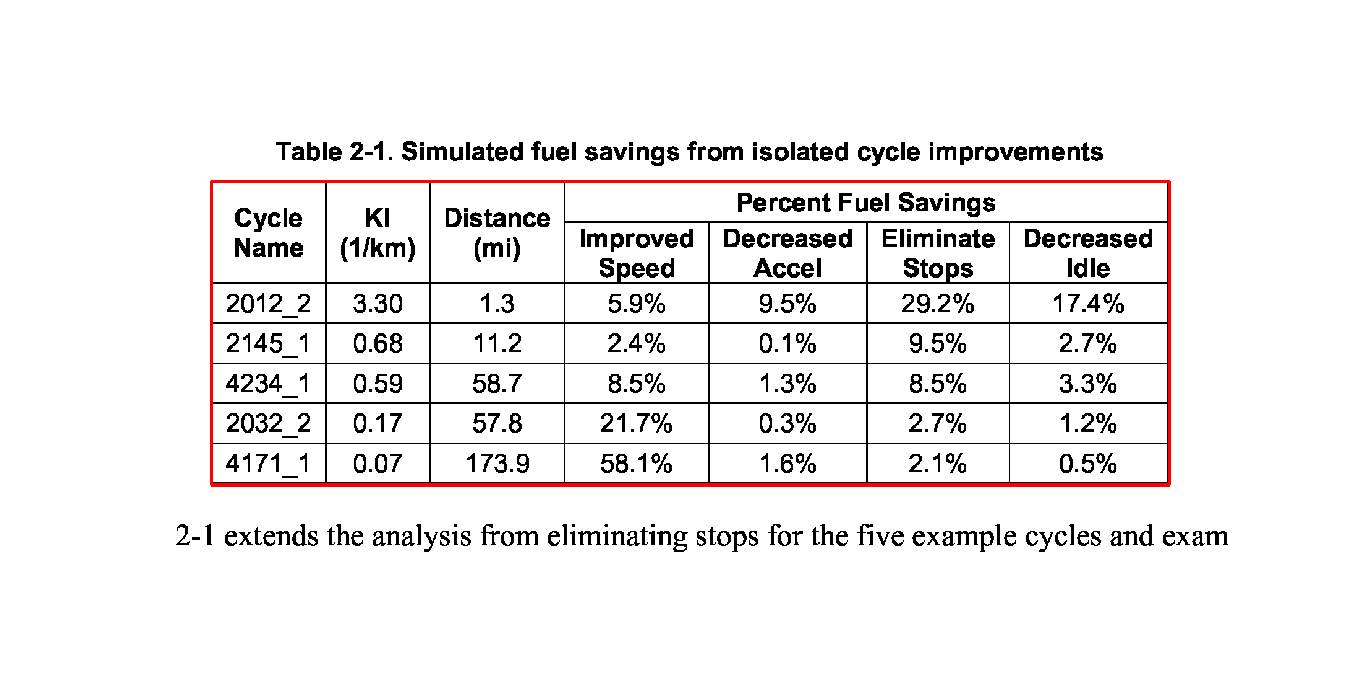
The plot below shows the bounding boxes of all the text elements found on the page (here the network parser running on a public-health table):
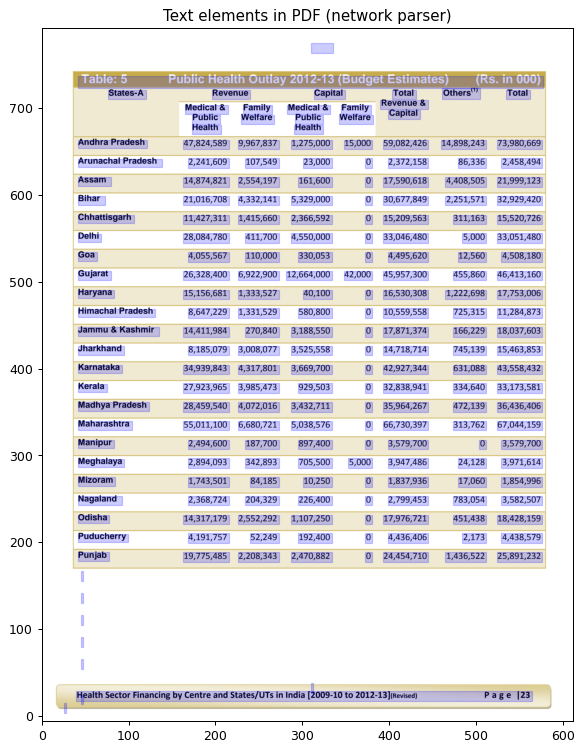
The network parser starts by identifying common horizontal or vertical coordinate alignments across these text elements. In other words it looks for bounding box rectangles which either share the same top, center, or bottom coordinates (horizontal axis), or the same left, right, or middle coordinates (vertical axis). See the generate method.
Once the parser found these alignments, it performs some pruning to only keep text elements that are part of a network - they have connections along both axis The idea is that it’s not enough for two elements to be aligned to belong to a table, for instance the lines of text in this paragraph are all left-aligned, but they do not form a network. The pruning is done iteratively, see “remove_unconnected_edges” method.
Once the network is pruned, the parser counts how many alignments each text element belongs to. The text element with the most connections is the starting point — the seed — of the next step. Finally, the parser measures how far the alignments are from one another, to determine a plausible search zone around each cell for the next stage of growing the table. See “compute_plausible_gaps” method.
n the next step, the parser iteratively “grows” a table, starting from the seed identified in the previous step. The bounding box is initialized with the bounding box of the seed, then it iteratively searches for text elements that are close to the bounding box, then grows the table to ingest them, until there are no more text elements to ingest. The two steps are:
Search: create a search bounding box by expanding the current table bounding box in all directions, based on the plausible gap numbers determined above. Grow: if a networked text element is found in this search area, expand the table bounding box so that it includes this new element.
The search area and the table bounding box grow starting from the seed. See method “search_table_body”.
Headers are often aligned differently from the rest of the table. To account for this, the network parser searches for text elements that are good candidates for a header section: these text elements are just above the bounding box of the body of the table, and they fit within the rows identified in the table body. See the method “search_header_from_body_bbox”.
Words that lie inside/outside the current column x ranges are then used to extend the current list of columns.
There are sometimes multiple tables on one page. So once a first table is identified, all the text edges it contains are removed, and the algorithm is repeated until no new network is identified.
Hybrid#
The hybrid parser aims to combine the strengths of the Network parser (identifying cells based on text alignments) and of the Lattice parser (relying on solid lines to determine tables rows and columns boundaries).
Hybrid calls both parsers, to get a) the standard table parse, b) the coordinates of the rows and columns boundaries, and c) the table boundaries (or contour).
If there are areas in the document where both lattice and network found a table, the hybrid parser uses the results from network, but enhances them based on the rows/columns boundaries identified by lattice in the area. Because lattice uses the solid lines detected on the document, the coordinates for b) and c) detected by Lattice are generally more precise. See the “_merge_bbox_analysis” method.
ML (Table Transformer)#
flavor='ml' is an optional neural backend for the tables the
heuristic parsers find hardest — dense borderless tables — and, with
OCR, for scanned / image-only PDFs. It is opt-in because it pulls
PyTorch: pip install 'camelot-py[ml]' (add [ocr] for scans).
Its guiding rule is the model supplies the structure, the page supplies the text:
The page is rendered to an image. A Table Transformer (TATR) detection model finds the table region(s); a second TATR model recognises the structure — rows, columns and spanning cells — as bounding boxes.
Those boxes are turned into the same column/row/spanning grid the other parsers build, then mapped from image space back to PDF coordinates.
Each cell’s text is filled from the PDF’s own text layer (the exact characters), reusing the same assignment step as every other flavor — so the model never emits a character of cell text and cannot hallucinate or alter a value. For scanned pages with no text layer,
ocr='auto'reads the text from the rendered image instead (still geometry + recognised text, never invented cells).
Because the structure half runs on the page image, flavor='ml' is the
only parser that works without a text layer at all.
Borderless accuracy#
On the borderless FinTabNet.c
benchmark (545 financial PDFs, bench/benchmark_fintabnet.py), the model
backend clears the ceiling the heuristic parsers plateau at:
flavor |
F1 |
TEDS |
row |
col |
|---|---|---|---|---|
ml |
0.750 |
0.371 |
0.235 |
0.570 |
network |
0.725 |
0.200 |
0.109 |
0.220 |
hybrid (combined) |
0.658 |
0.198 |
0.109 |
0.217 |
(TEDS/row/col from bench/_metrics.py; TEDS here is a
difflib cell-text proxy, not exact tree-edit distance, so the absolute
values are conservative — the point is the relative gap: ml roughly
doubles borderless TEDS over network/hybrid.) The trade-off is
speed (~1 s/page with a GPU vs tens of ms for network) and the optional
PyTorch dependency, which is why it is opt-in rather than the default.